- Introduction
- Postman
- Pagination
- Parallel retrieval
- Requests throttling
- API versions
- Changelog
- 2026-07-10
- Simulator integration API
- 2026-07-09
- Atlas AI (beta)
- Chat Completions API (alpha)
- Atlas AI (internal)
- Cognite Functions
- 2026-07-06
- SAP Writeback
- 2026-07-02
- Atlas AI (beta)
- Atlas AI (internal)
- 2026-06-23
- Atlas AI (beta)
- 2026-06-19
- Data Products
- 2026-06-17
- Groups API
- Token API
- 2026-06-15
- Data Workflows
- 2026-06-12
- Postgres gateway
- 2026-05-28
- Data Products
- Entity matching
- 2026-05-27
- Atlas AI
- 2026-05-26
- Data Modeling API
- 2026-05-22
- Chat Completions API (alpha)
- Agents API (beta)
- 2026-05-21
- Functions
- 2026-05-18
- Atlas AI
- Token API
- 2026-05-12
- Atlas AI
- Functions
- 2026-05-08
- Groups API
- Data Workflows (internal)
- 2026-05-07
- Data Modeling API
- Agent APIs (beta)
- 2026-05-06
- Data Workflows (beta)
- Cognite Functions
- 2026-05-05
- Signals
- Seismic
- 2026-05-04
- Simulator integration API
- 2026-04-30
- Streams and Records API
- 2026-04-23
- Cognite Functions
- Agent APIs (beta)
- 2026-04-21
- Documents AI API
- 2026-04-15
- Data Modeling API
- 2026-04-10
- Cognite Functions
- 2026-03-25
- Streams and Records API
- 2026-03-24
- Data Modeling API
- 2026-03-23
- Streams and Records API
- 2026-03-20
- Data Workflows (beta)
- 2026-03-17
- Transformations
- 2026-03-12
- 3D API (beta)
- 2026-03-09
- Agent APIs (beta)
- 2026-03-06
- Agent APIs (beta)
- 2026-03-04
- Agent APIs (beta)
- 2026-01-20
- Data Modeling API
- 2026-01-15
- Data Workflows
- 2026-01-13
- Hosted Extractors
- 2026-01-06
- 3D API (beta)
- 2025-12-06
- Data Workflows
- 2025-12-05
- 3D API (beta)
- 2025-11-25
- Data Workflows
- 2025-11-28
- Data Modeling API
- 2025-11-26
- Agent APIs (beta)
- 3D API (beta)
- 2025-11-21
- Hosted extractors API
- 2025-11-20
- Agent APIs (beta)
- 2025-11-18
- Simulator integration API
- 2025-11-13
- 3D API
- 2025-11-11
- Streams and Records API
- 2025-11-06
- Simulator integration API
- 2025-11-04
- Streams and Records API
- 2025-10-29
- Simulator integration API
- 2025-10-07
- Agents API
- 2025-10-03
- Cognite Functions
- 2025-10-02
- Agent APIs (beta)
- 2025-10-01
- Data Modeling API
- 2025-09-29
- Agent APIs (beta)
- 2025-09-26
- Time Series API
- 2025-09-09
- Data Modeling API
- 2025-09-08
- Default runtime in Cognite functions
- 2025-09-02
- Data Modeling API
- 2025-08-26
- Data sets API
- 2025-09-02
- 3D API
- 2025-08-28
- Agent APIs (beta)
- 2025-08-29
- Simulator integration API
- 2025-09-02
- IAM (Identity and access management)
- 2025-08-20
- 3D API
- 2025-07-21
- Data Modeling API
- 2025-07-18
- Data Modeling API
- 2025-07-04
- IAM (Identity and access management)
- 2025-06-30
- Data Modeling API
- 2025-05-21
- Agent APIs
- Documents AI API
- 2025-05-26
- Simulator integration API
- 2025-05-21
- Simulator integration API
- 2025-05-15
- 3D API
- 2025-05-15
- Transformations
- 2025-05-09
- 3D Api
- 2025-04-30
- 3D Api
- 2025-04-23
- Entity Matching
- 2025-03-25
- Agent APIs
- 2025-03-25
- Documents AI
- 2025-03-13
- Documents API
- 2025-03-12
- Time Series API
- 2025-02-17
- PostgreSQL Gateway API
- 2025-02-15
- Principals API
- 2025-01-20
- Hosted Extractors API
- 2024-12-03
- SAP Writeback API
- Hosted Extractors API
- 2024-11-19
- Simulator integration API
- Documents AI APIs
- 2024-11-14
- User profiles
- 2024-11-12
- Organizations and Projects
- 2024-10-22
- Hosted Extractors API
- 2024-10-14
- AWS Cognito support
- 2024-10-11
- Organizations and Projects
- 2024-09-31
- Time Series API
- 2024-09-19
- Contextualization / Vision
- 2024-09-14
- Simulator integration API
- 2024-09-13
- Contextualization / Engineering diagrams
- 2024-09-12
- Files API
- SAP Writeback
- 2024-09-10
- Time Series API
- Subscriptions API
- 2024-09-02
- Files API
- 2024-08-23
- Data Workflows
- 2024-08-20
- Data Workflows
- 2024-07-18
- Organizations and Projects
- 2024-06-24
- Data Modeling
- 2024-06-17
- Data Modeling
- 2024-06-13
- Organizations and Projects
- Time Series
- 2024-05-24
- Organizations and Projects
- User profiles
- Projects
- 2024-05-23
- Time series
- 2024-05-02
- Postgres gateway
- 2024-05-01
- Time series
- 2024-04-02
- Groups
- 2024-03-19
- Engineering diagrams (beta)
- 2024-03-11
- Default runtime in Cognite functions
- 2024-03-06
- Files
- 2024-02-29
- Assets
- 2024-02-20
- Data Modeling
- 2024-02-19
- Time series
- 2024-02-08
- Hosted Extractors
- 2024-02-01
- Synthetic time series
- 2024-01-16
- Sessions
- 2024-01-02
- Data Modeling
- 2023-12-12
- Data Modeling
- 2023-12-11
- Time series
- 2023-12-06
- Time series
- 2023-11-30
- Hosted extractors
- 2023-11-21
- Units Catalog
- 2023-11-17
- Documents
- 2023-11-08
- Engineering diagrams
- 2023-10-23
- Files
- 2023-10-17
- Events
- 2023-10-10
- Entity matching
- Vision (Contextualization)
- 2023-10-05
- Hosted extractors
- 2023-09-27
- 3D
- 2023-08-25
- Transformations
- 2023-08-22
- Functions
- 2023-08-22
- Time series
- 2023-08-10
- Time series
- Sequences
- 2023-08-08
- Assets
- Events
- Documents
- 2023-06-27
- IAM (Identity and access management)
- 2023-06-05
- Data Modeling
- Time series
- Sequences
- 2023-05-19
- Transformations
- 2023-04-24
- Transformations
- 2023-05-04
- Annotations
- 2023-04-18
- All resources
- Assets
- Events
- Documents
- 2023-04-12
- Sessions
- 2023-04-04
- Transformations
- 2023-03-06
- Documents
- 2023-02-03
- Seismic
- 2023-02-07
- Documents
- 2023-01-18
- 3D
- 2023-01-17
- Authentication
- 3D
- 2023-01-12
- Documents
- 2023-01-10
- Documents
- 2023-01-09
- Documents
- 2023-01-06
- Documents
- 2023-01-02
- Documents
- 2022-12-06
- 3D
- 2022-12-16
- Time series
- 2022-11-29
- Events
- 2022-11-17
- Time series
- 2022-10-14
- Geospatial
- 2022-10-11
- Transformations
- 2022-10-06
- IAM (Identity and access management)
- 2022-09-09
- Vision (Contextualization)
- 2022-08-12
- Time series
- 2022-07-21
- Transformations
- 2022-06-21
- Annotations (Data organization)
- 2022-07-07
- Events
- 2022-06-13
- IAM (Identity and access management)
- 2022-05-20
- Documents
- 2022-05-12
- Documents
- 2022-04-11
- Documents
- 2022-03-15
- Sequences
- 2022-03-02
- Sequences
- 2022-02-08
- Time series
- 2022-02-07
- Documents
- 2022-01-25
- Documents
- 2022-01-24
- Time series
- 2021-12-07
- Transformations
- 2021-11-22
- Contextualization
- 2021-11-17
- 3D
- 2021-10-13
- Raw
- 2021-10-05
- Extraction Pipelines
- 2021-09-28
- Sequences
- Time series
- 2021-08-18
- IAM (Identity and access management)
- 2021-08-12
- Relationships
- 2021-07-01
- 3D
- 2021-06-29
- Labels
- 2021-06-08
- Sequences
- 2021-06-01
- Assets
- 2021-04-28
- Time series
- 2021-04-12
- IAM (Identity and access management)
- 2021-04-06
- Authentication
- 2021-03-22
- 2021-03-10
- 3D
- 2021-02-26
- Entity matching
- 2020-12-22
- Files
- 2020-10-20
- Files
- 2020-08-29
- Files
- 2020-08-05
- Files
- 2020-07-08
- IAM (Identity and access management)
- 2020-07-01
- Events
- 2020-06-29
- Labels
- Assets
- Time series
- 2020-04-28
- Events
- 2020-03-12
- General
- Groups
- 2020-03-10
- 3D
- 2020-02-25
- Assets
- Events
- 2020-02-12
- Assets
- 2020-02-10
- Assets
- 2019-12-09
- General
- 2019-12-04
- Assets
- 2019-11-18
- Events
- 2019-11-12
- Access control
- 2019-10-31
- Assets
- Time Series
- 2019-10-23
- Files
- 2019-10-18
- Time Series
- 2019-10-16
- Events
- 2019-10-02
- Sequences
- 2019-09-30
- 3D
- 2019-09-23
- Files
- 2019-09-16
- Assets and Events
- 2019-08-22
- 3D
- 2019-08-21
- Files
- Assets
- 2019-08-15
- 3D
- 2019-07-24
- Files
- 2019-07-15
- Time series
- 2019-07-11
- General
- Assets
- Events
- Files
- Raw
- Time series
- IAM (Identity and access management)
- 3D
- Changelog
- Organizations
- External identity providers (IdP)
- Users
- Organization hierarchy
- Projects
- Allowed clusters
- Organization admins
- Authentication for this API
- putAllow/forbid admins of an organization to create projects
- putAllow/forbid admins of an organization to create sub-organizations
- postCreate an organization
- postCreate an organization
- delDelete an organization
- postDelete an organization
- getList child organizations
- getList child organizations
- getRetrieve an organization
- getRetrieve an organization
- putUpdate the admin group ID for an organization
- putUpdate the allowed clusters for an organization
- putUpdate the IdP configuration for an organization
- Projects
- Organizations
- Principals
- Groups
- Security categories
- Sessions
- Token
- User profiles
- get(deprecated) Get the user profile of the principal issuing the request
- getGet the user profile of the principal issuing the request
- getList all user profiles in the current project
- getList users in the organization
- postRetrieve profiles by ID in the current project
- postSearch user profiles in the current project
- Data Modeling
- Data models
- Spaces
- Views
- Containers
- postCreate or update containers
- postDelete constraints from containers
- postDelete containers
- postDelete indexes from containers
- postInspect containers
- getList containers defined in the project
- postRetrieve containers by their external ids
- postRetry failed container constraints
- postRetry failed indexes
- postRetry failed property constraints
- Instances
- Statistics
- Streams
- Records
- Assets
- Time series
- Synthetic Time Series
- Data point subscriptions
- Events
- Files
- Rate and concurrency limits
- Translating RPS into data speed
- Use of Partitions / Parallel Retrieval
- postAggregate files
- postComplete multipart upload
- postDelete files
- postDownload files
- postFilter files
- getGet icon
- postGet multipart file upload link
- postGet upload file link
- getList files
- getRetrieve a file by its ID
- postRetrieve files
- postSearch files
- postUpdate files
- postUpload file
- postUpload multipart file
- Sequences
- Geospatial
- postAggregate features
- postCompute
- postCreate Coordinate Reference Systems
- postCreate feature types
- postCreate features
- postDelete a raster from a feature property
- postDelete Coordinate Reference Systems
- postDelete feature types
- postDelete features
- postFilter all features
- postGet a raster from a feature property
- postGet Coordinate Reference Systems
- getGet features
- getList Coordinate Reference Systems
- postList feature types
- putPut a raster into a feature property
- postRetrieve feature types
- postRetrieve features
- postSearch and stream features
- postSearch features
- postUpdate feature types
- postUpdate features
- Entity matching
- postCreate entity matcher model
- postDelete entity matcher model
- postFilter models
- getList entity matching models
- postPredict matches
- postRe-fit entity matcher model
- getRetrieve an entity matching model by the ID of the model
- getRetrieve entity matcher predict results
- postRetrieve entity matching models
- postUpdate entity matching models
- Entity matching pipelines
- Engineering diagrams
- Vision
- Advanced joins
- Concepts
- Advanced joins
- Matches
- Matchers
- Jobs
- postCreate advanced joins
- postCreate matches
- postDelete advanced joins
- postDelete matches
- postEstimate contextualization quality
- getList advanced joins
- getList matches
- postMeasure mapped percentages
- getRetrieve advanced join run status
- getRetrieve estimate quality status
- getRetrieve mapped percentage status
- getRetrieve suggested improvements
- postRun an advanced join
- postSuggest improvements
- postUpdate advanced joins
- Entity matching
- Raw
- Request and concurrency limits
- URI formats used for lineage
- postCreate databases
- postCreate tables in a database
- postDelete databases
- postDelete rows in a table
- postDelete tables in a database
- postInsert rows into a table
- getList databases
- getList tables in a database
- getRetrieve cursors for parallel reads
- getRetrieve row by key
- getRetrieve rows from a table
- Extraction Pipelines
- Extraction Pipelines Runs
- Extraction Pipelines Config
- Extractors
- Raw
- Integrations
- postCheck in
- postCreate config revision.
- postCreate Integrations
- postDelete Integrations
- postExtraction pipeline runs
- getFetch config revision
- getGet Task History
- getList config revisions
- getList Errors
- getList Integrations
- postReport Extractor Info
- postRetrieve Integrations
- getSync Integration History
- postUpdate Integrations
- Integrations
- Simulators
- Simulator Integrations
- Simulator Models
- postAggregate Simulator Models
- postCreate Simulator Model
- postCreate Simulator Model Revision
- postDelete Simulator Model
- postFilter Simulator Model Revisions
- postFilter Simulator Models
- postRetrieve Simulator Model
- postRetrieve Simulator Model Revision Data
- postRetrieve Simulator Model Revisions
- postUpdate Simulator Model
- Simulator Routines
- Simulation Runs
- Simulator Logs
The assets resource type stores digital representations of objects or groups of objects from the physical world. Assets are organized in hierarchies. For example, a water pump asset can be a part of a subsystem asset on an oil platform asset.
Both the rate of requests (denoted as request per second, or ‘rps’) and the number of concurrent (parallel) requests are governed by limits,
for all CDF API endpoints. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
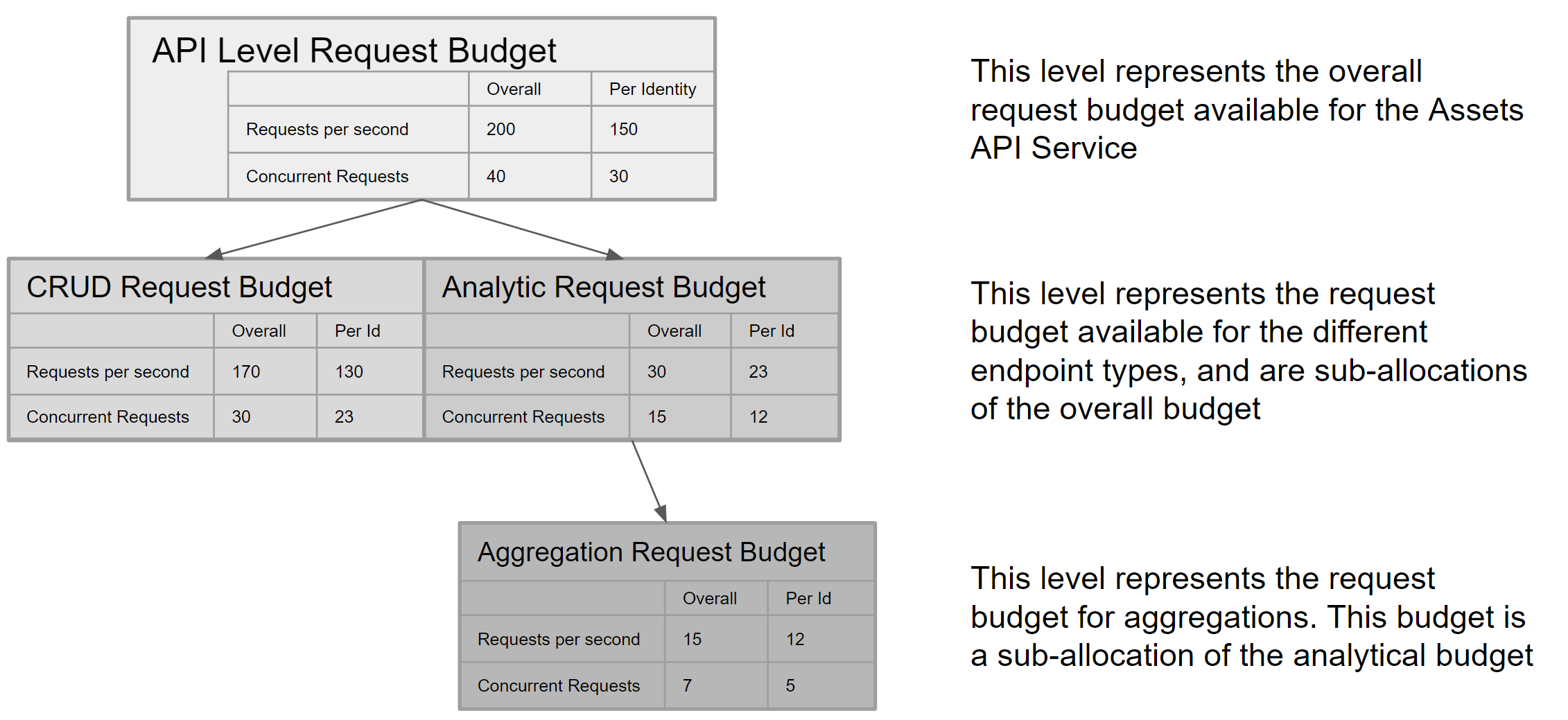
Limits are defined at both the overall API service level, and on the API endpoints belonging to the service.
Some types of requests consume more resources (compute, storage IO) than others, and where a service handles
multiple concurrent requests with varying resource consumption.
For example, ‘CRUD’ type requests (Create, Retrieve, Request ByIDs, Update and Delete) are far less resource
intensive than ‘Analytical’ type requests (List, Search and Filter) and in addition, the most resource
intensive Analytical endpoint of all, Aggregates, receives its own request budget within the overall Analytical request budget.
The version 1.0 limits for the overall API service and its constituent endpoints are illustrated in the diagram below.
These limits are subject to change, pending review of changing consumption patterns and resource availability over time:
A single request may retrieve up to 1000 items. In the context of Assets, 1 item = 1 asset record
Therefore, the maximum theoretical data speed at the top API service level is 200,000 items per second for all consumers,
and 150,000 for a single identity or client in a project.
As a general guidance, Parallel Retrieval is a technique that should be used where due to query complexity, retrieval of data in a single request session turns out to be slow. By parallelizing such requests, data retrieval performance can be tuned to meet the client application needs. Parallel retrieval may also be used where retrieval of large sets of data is required, up to the capacity limits defined for a given API service. For example (using the Assets API request budget):
- A single request may retrieve up to 1000 items
- Up to 23 requests per second may be issued for an analytical query (per identity), such as when using /list or /filter API endpoints
- This provides a theoretical maximum of 23,000 items read per second per identity
- The query complexity may result in it taking longer than 1s to read or write 1000 items in a single request
- Therefore, it is appropriate to specify the query to retrieve a lower number of items per request, and retrieve more items in parallel, up to the theoretical maximum performance of 23,000 items per second.
Important Note:
Parallel retrieval should be only used in situations where, due to query complexity,
a single request flow provides data retrieval speeds that are significantly less than the theoretical maximum.
Parallel retrieval does not act as a speed multiplier on optimally running queries. Regardless of the number
of concurrent requests issued, the overall requests per second limit still applies.
So for example, a single request returning data at approximately 18,000 items per second will only
benefit from adding a second parallel request, the capacity of which goes somewhat wasted
as only an additional 5,000 items per second will return before the request rate budget limit is reached.