Events objects store complex information about multiple assets over a time period.
Typical types of events that would be stored in this service might include Alarms, Process Data, and Logs.
For the storage of low volume, manually generated, schedulable activities (such as maintenance schedules,
work orders or other ‘appointment’ type activities, the Data Modeling service is now recommended.
Important Note:
Events and Time Series are somewhat closely related in that both are high volume types of data,
capable of recording data in microsecond resolutions. However, Events is not recommended as a Time Series store,
such as where the data flow is from a single instance of sensors (i.e. temperature, pressure, voltage),
simulators or state machines (on, off, disconnected, etc).
Time Series offers very low latency read and write performance, as well as specialised filters and aggregations that
are tailored to the analysis of time series data.
An event’s time period is defined by a start time and end time, both millisecond timestamps since the UNIX epoch.
The timestamps can be in the future. In addition, events can have a text description as well as arbitrary metadata and properties.
When storing event information in metadata, it should be considered that all data is stored as string format.
Note:
In Events API, timestamps are treated as strings when added to metadata fields and aren’t converted to the user’s local time zone.
**Caveats:**
Due to the eventually consistent nature of Asset IDs stored in Events,
it should be noted that Asset ID references obtained from the Events API may
occasionally be invalid (such as if an Asset ID is deleted,
but the reference to that ID remains in the Event record for a time).
Asset references obtained from an event - through asset ids - may be invalid, simply by the non-transactional nature of HTTP. They are maintained in an eventual consistent manner.
Both the rate of requests (denoted as request per second, or ‘rps’) and the number of concurrent (parallel) requests are governed by limits,
for all CDF API endpoints. If a request exceeds one of the limits,
it will be throttled with a 429: Too Many Requests response. More on limit types
and how to avoid being throttled is described
here.
Limits are defined at both the overall API service level, and on the API endpoints belonging to the service.
Some types of requests consume more resources (compute, storage IO) than others, and where a service handles
multiple concurrent requests with varying resource consumption.
For example, ‘CRUD’ type requests (Create, Retrieve, Request ByIDs, Update and Delete) are far less resource
intensive than ‘Analytical’ type requests (List, Search and Filter) and in addition, the most resource
intensive Analytical endpoint of all, Aggregates, receives its own request budget within the overall Analytical request budget.
The version 1.0 limits for the overall API service and its constituent endpoints are illustrated in the diagram below.
These limits are subject to change, pending review of changing consumption patterns and resource availability over time:
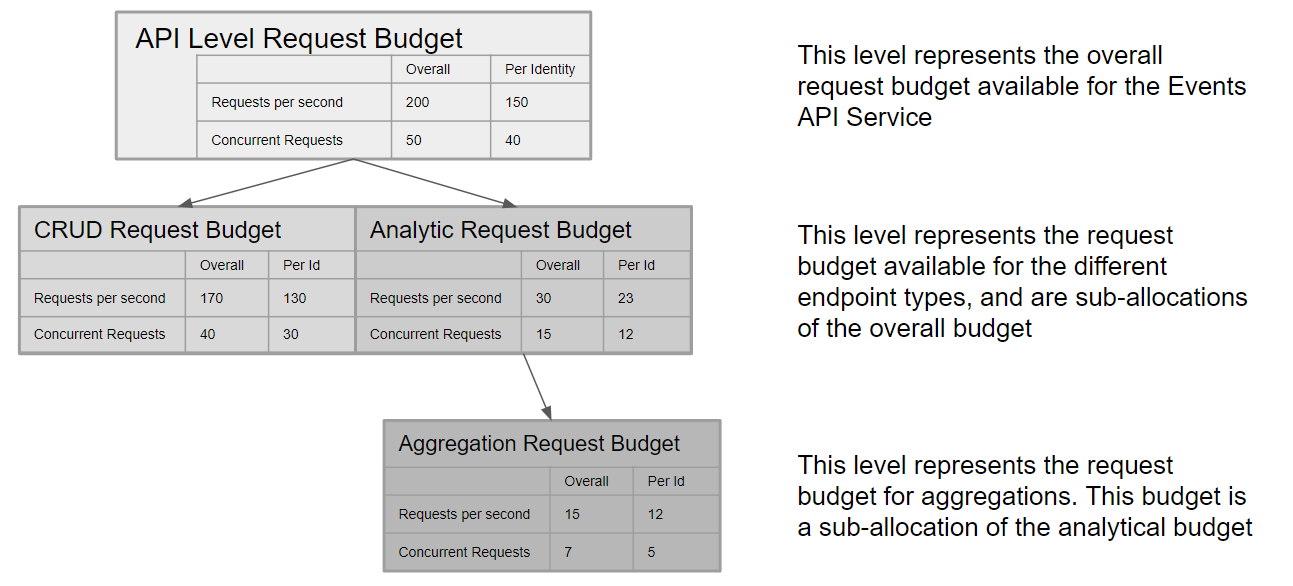
A single request may retrieve up to 1000 items. In the context of Events, 1 item = 1 event record
Therefore, the maximum theoretical data speed at the top API service level is 200,000 items per second for all consumers,
and 150,000 for a single identity or client in a project.
As a general guidance, Parallel Retrieval is a technique that should be used where due to query complexity, retrieval of data in a single request session turns out to be slow. By parallelizing such requests, data retrieval performance can be tuned to meet the client application needs. Parallel retrieval may also be used where retrieval of large sets of data is required, up to the capacity limits defined for a given API service. For example (using the Events API request budget):
- A single request may retrieve up to 1000 items
- Up to 23 requests per second may be issued for an analytical query (per identity), such as when using /list or /filter API endpoints
- This provides a theoretical maximum of 23,000 items read per second per identity
- The query complexity may result in it taking longer than 1s to read or write 1000 items in a single request
- Therefore, it is appropriate to specify the query to retrieve a lower number of items per request, and retrieve more items in parallel, up to the theoretical maximum performance of 23,000 items per second.
Important Note:
Parallel retrieval should be only used in situations where, due to query complexity,
a single request flow provides data retrieval speeds that are significantly less than the theoretical maximum.
Parallel retrieval does not act as a speed multiplier on optimally running queries. Regardless of the number
of concurrent requests issued, the overall requests per second limit still applies.
So for example, a single request returning data at approximately 18,000 items per second will only
benefit from adding a second parallel request, the capacity of which goes somewhat wasted
as only an additional 5,000 items per second will return before the request rate budget limit is reached.